
How good is Docket Recognition in GPT-4 Vision?
Overview
OpenAl has introduced groundbreaking capabilities of image understanding within ChatGPT for Plus and Enterprise users. The cutting-edge image capabilities are driven by multimodal GPT-4. This model leverages advanced reasoning to interpret diverse visual content, including photos, screenshots, and text-image documents. Our focus is on researching and assessing the ability of GPT-4 Vision to analyse image content and provide precise responses to queries.
Key Concepts
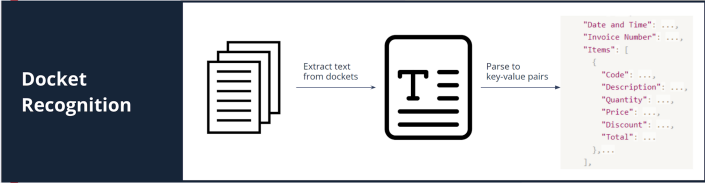
Docket recognition means extracting data from dockets, invoices, or receipts, and parsing them to a digital format. Docket content can be printed or handwritten. Our goal was to assess the accuracy of docket recognition using GPT-4 Vision. We compared the accuracy of GPT-4 Vision with Amazon Textract, one of leading cloud-based services for extracting printed and handwritten content. Additionally, we gauged the query-answering capabilities of both services using the same testing dockets.
Deep Dive
We tested on 10 dockets, evenly split between 5 printed and 5 handwritten text samples. Additionally, we evaluated the capabilities of GPT-4 Vision and Textract in addressing 3 questions regarding the content:
- Does this docket contain meal break?
- Is this docket for materials, labour, or plant/ equipment?
- Does this docket have a start and end time?
Notably, while OpenAl has yet to disclose the pricing for GPT-4 image processing, AWS Textract offers a pricing structure of USD 50 per 1000 pages.
Setup & Testing
Our exploration used GPT-4 Vision and Textract to extract key-value pairs from our testing dockets. GPT-4 Vision achieved an 88.3% accuracy rate for handwritten dockets and 93.6% for printed ones. The accuracy of Textract was 50.4% for handwritten dockets and 60.8% for printed ones.
Furthermore, when it comes to answering queries, GPT-4 Vision achieved 100% accuracy, whereas Textract exhibited a range between 0% and 50%, with an average accuracy of 11.7%.
Hitting The Limits
The accessibility of GPT-4 Vision is currently limited to ChatGPT web, iOS, and Android applications. OpenAl does not have API support at present.
Additionally, while GPT-4 Vision excels in extracting printed text, its accuracy in handling handwritten content is slightly lower, reflecting the challenge of interpreting handwritten text, compared to printed text.
What’s Next?
GPT-4 Vision showcases impressive accuracy in text extraction and groundbreaking capabilities in responding to queries from images. The anticipation for API support for GPT-4 Vision is high, as it promises to unlock even more exciting possibilities and applications using this technology.
What’s the verdict?
OpenAI GPT-4 Vision is currently in an early stage, but its demonstrated potential in image comprehension is truly remarkable.
This latest iteration of GPT-4 seamlessly integrates image processing with language understanding, opening up a world of possibilities.
It is clear that docket recognition is just the tip of the iceberg, as this technology holds the promise to revolutionise various applications across industries.













{kind=link}